在当代社会研究中,个体生命轨迹愈发呈现出多样化与非线性的特征:人们的教育路径不再单一,职业经历频繁变动,婚育模式也更加多元。
在这一背景下,如何量化这种轨迹的复杂性与多样性?
信息熵作为衡量“不确定性”的核心指标,提供了一种简洁而有力的解决方案。
本系列文章将围绕“信息熵在社会序列分析中的应用”展开,结合实际示例,从通用熵的基本概念,到横截面熵、纵向熵、局部熵,再到综合指标与实战案例,系统讲解如何用熵来刻画个体路径、群体差异和社会变迁。
局部熵(Local Entropy)可以帮助我们识别生命历程中的关键转折期。你可能会问,为什么这个函数跟上面的纵向熵是共用的同一个函数 seqient()?因为它们都衡量的是单个序列的复杂度,只是特点不同,函数使用的参数也不同。
局部熵是在序列分析中用于识别”不稳定性热点”的一种方法。它通过分析序列的局部窗口(比如3年)来揭示生命轨迹中变化最剧烈的时期。
- 局部熵其实可以称为浓缩成窗口阶段版的纵向熵,因为纵向熵是所有时间点都会计算这一个时间点内所有人的平均熵。
- 但局部熵则是不计算每个时间点,而是将比如这里6个时间点浓缩成三个时间窗口,计算每个时间窗口的所有人的平均熵
因此,相比于纵向熵是直接:
# 计算所有序列的纵向熵long_entropies <- seqient(myseq)局部熵,则是需要选择合适的窗口大小:
基本的局部熵计算:
# 使用seqient函数计算局部熵# h参数定义滑动窗口的大小local_entropy <- seqient(myseq, h=3)更详细的局部熵分析:
# 更复杂的局部熵计算local_entropy <- seqsloc(myseq, method="entropy", # 使用熵作为局部不确定性度量 window=3, # 窗口大小为3 weighted=TRUE) # 是否使用加权方法当然,我们肯定还是要可视化局部熵:
# 绘制局部熵plot(local_entropy, main="生命历程局部不确定性", xlab="时间/年龄", ylab="局部熵")关键参数解释:
h或window:滑动窗口大小method:计算局部不确定性的方法(如熵)weighted:是否使用加权方法
具体理解关键特征#
1. 窗口分析#
窗口(Window)是一种分析方法,通过在数据序列中移动固定大小的区间来捕捉局部特征。
典型应用场景
- 社会学研究
- 追踪个人职业生涯的关键转折期
- 分析教育、婚姻、职业状态的变化
- 经济学
- 分析职业流动性
- 研究收入变化趋势
- 追踪就业市场的动态变化
- 生命历程研究
- 识别关键生命阶段的转型
- 研究不同年龄段的生活轨迹变化
窗口分析的具体示例
# 假设追踪一个人的职业生涯序列career_sequence = [ '学生', '学生', '实习', '兼职', '全职', '全职', '失业', '继续教育', '全职']
# 3年窗口分析def analyze_window(sequence, window_size=3): windows = [] for i in range(len(sequence) - window_size + 1): window = sequence[i:i+window_size] windows.append(window) return windows
# 计算每个窗口的熵def calculate_window_entropy(windows): entropies = [] for window in windows: # 计算窗口内状态分布的熵 unique, counts = np.unique(window, return_counts=True) probabilities = counts / len(window) entropy = -np.sum(probabilities * np.log2(probabilities)) entropies.append(entropy) return entropies窗口分析的关键特征
- 灵活性
- 窗口大小可调(3年、5年等)
- 根据研究目的选择合适窗口
- 局部聚焦
- 不看整个序列
- 关注特定时间段的变化
- 动态捕捉
- 展示随时间的变化趋势
- 揭示隐藏的转折点
不同学科的窗口分析应用
- 心理学
- 追踪个人心理状态变化
- 分析应对压力的能力
- 流行病学
- 分析疾病传播的动态
- 追踪健康状况的变化
- 金融学
- 分析股票价格波动
- 研究市场趋势
窗口大小的选择
- 太小:可能捕捉不到有意义的变化
- 太大:会丢失细节
- 最佳窗口大小取决于:
- 研究问题
- 数据特征
- 理论背景
实践建议
- 尝试不同窗口大小
- 结合理论背景
- 进行敏感性分析
窗口分析本质上是一种动态、灵活的方法,帮助我们从宏观序列中提取局部特征,揭示复杂系统的微观变化机制。
2. 变化检测#
-
局部熵高,则意味着在该时期:
- 状态变化频繁
- 生活轨迹不确定性增加
- 可能正经历重大转折
-
相反,如果局部熵低,则意味着在该时期:
- 状态稳定性:生活轨迹高度可预测,状态变化极少或几乎没有变化
- 比如职业、角色、生活状态保持不变,呈现出明显的连续性和稳定性
实际意义举例#
假设我们在追踪一个人的职业生涯:
年龄 状态序列20岁 学生 → 学生 → 学生21岁 学生 → 实习 → 兼职22岁 全职 → 全职 → 全职23岁 全职 → 失业 → 继续教育24岁 继续教育 → 全职 → 全职局部熵分析可能显示:
- 21-22岁:熵值较高(状态变化多)
- 22-23岁:熵值峰值(职业状态剧烈变化)
- 23-24岁:熵值降低(趋于稳定)
import matplotlib.pyplot as plt
def generate_more_realistic_sequences(n_sequences=100, sequence_length=6): """ 生成更贴近生命历程的序列 模拟典型的生命轨迹变化 """ sequences = [] states = ['学生', '实习', '兼职', '全职', '失业', '继续教育']
for _ in range(n_sequences): # 模拟典型生命轨迹 seq = [] # 早期:变化多 seq.extend(['学生', '学生', '实习'])
# 中期:逐渐稳定 if np.random.random() < 0.7: seq.extend(['兼职', '全职', '全职']) else: seq.extend(['全职', '失业', '继续教育'])
# 确保序列长度一致 while len(seq) < sequence_length: seq.append(seq[-1])
sequences.append(seq)
return sequences
def calculate_local_entropy(sequences, window_size=3): """ 计算序列的局部熵 """ local_entropies = [] for t in range(len(sequences[0]) - window_size + 1): local_windows = [seq[t:t+window_size] for seq in sequences]
window_entropies = [] for window in local_windows: unique, counts = np.unique(window, return_counts=True) probabilities = counts / len(window)
window_entropy = -np.sum(probabilities * np.log2(probabilities)) window_entropies.append(window_entropy)
local_entropies.append(np.mean(window_entropies))
return local_entropies
# 生成序列sequences = generate_more_realistic_sequences(n_sequences=100, sequence_length=6)
# 计算局部熵local_entropies = calculate_local_entropy(sequences)
# 可视化plt.figure(figsize=(10, 6))plt.plot(local_entropies, marker='o')plt.title('Local Entropy of Life Course Sequences')plt.xlabel('Time Window')plt.ylabel('Local Entropy')plt.grid(True)
# 修改 x 轴刻度为整数plt.xticks(range(len(local_entropies)), range(len(local_entropies)))
plt.savefig('local_entropy.png', dpi=300)plt.show()这段代码实现了局部熵的计算和可视化,具体解释如下:
假设追踪100名毕业生的职业状态:
- 熵值波动反映职业轨迹的变化程度
- 高峰可能对应:
- 第一份工作
- 职业转型期
- 继续教育阶段
假设其中的一个人的职业生涯序列是:
[学生, 学生, 实习, 兼职, 全职, 全职, 失业, 继续教育, 全职]对于窗口大小为3的情况:
- 第一个窗口
[学生, 学生, 实习]
- 状态变化:从学生到实习
- 熵值可能较低(状态相对集中)
- 第二个窗口
[学生, 实习, 兼职]
- 状态变化:从学生到兼职
- 熵值可能增加(状态变化更多)
- 第三个窗口
[实习, 兼职, 全职]
- 状态变化:从实习到全职
- 熵值可能较高(状态转换明显)
下面图像展示了这位同学的的局部熵演变情况(不是所有人)
- X轴:连续的时间窗口
- Y轴:每个窗口的平均熵值
熵值 ↑ | * | * * | * * +-------------------→ 时间窗口 1 2 3 4 5而总体生成的100个毕业生的局部熵图像,则长下面这样:
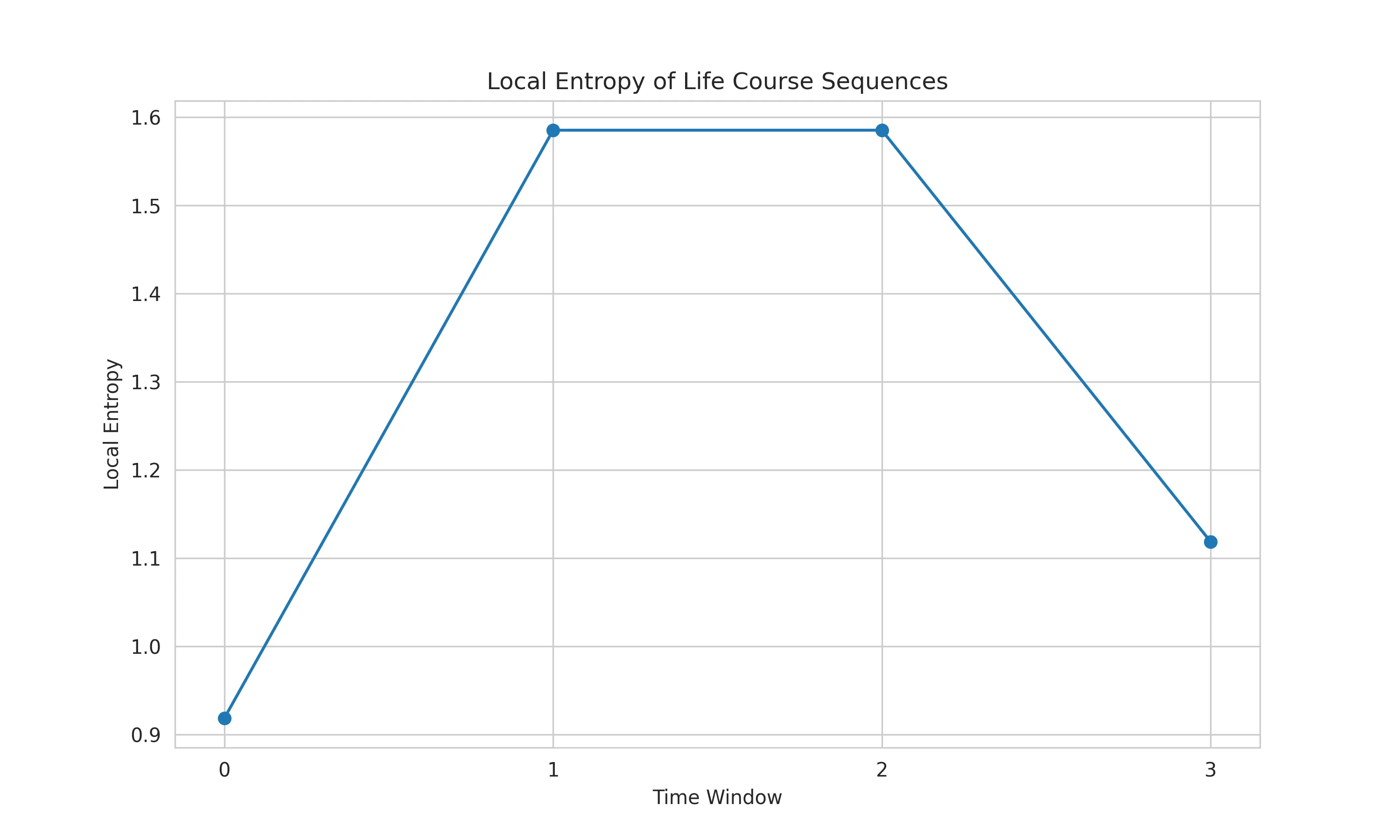
代码详细解析:
- 输入参数
sequences:多个个体的状态序列window_size:滑动窗口大小(默认3)
- 计算过程
for t in range(len(sequences[0]) - window_size + 1):
- 对每个可能的时间窗口进行遍历
- 例如,对于长度6的序列,我们分成了3个时间窗口,分别为:
- 第1-3个时间点
- 第2-4个时间点
- 第3-5个时间点
- 局部窗口提取
local_windows = [seq[t:t+window_size] for seq in sequences]
- 从每个序列中提取当前窗口
- 每个窗口包含所有序列在特定时间段的状态
- 熵值计算
# 计算窗口内状态分布unique, counts = np.unique(window, return_counts=True)probabilities = counts / len(window)# 计算熵window_entropy = -np.sum(probabilities * np.log2(probabilities))
- 统计窗口内各状态出现频率
- 使用信息论公式计算熵
- 熵越高,状态分布越均匀,不确定性越大
- 平均局部熵
local_entropies.append(np.mean(window_entropies))
- 计算所有序列在该窗口的平均熵值
- 也就是说,每一个窗口的值,是所有样本的平均局部熵
- 局部熵其实可以称为浓缩成窗口阶段版的纵向熵,因为纵向熵是所有时间点都会计算这一个时间点内所有人的平均熵。
- 但局部熵则是不计算每个时间点,而是将比如这里6个时间点浓缩成三个时间窗口,计算每个时间窗口的所有人的平均熵
- 可视化
plt.plot(local_entropies, marker='o')- X轴:时间窗口序号
- Y轴:该时间窗口的平均局部熵
- 峰值表示生命历程中变化最剧烈的时期
局部熵 vs 纵向熵#
- 纵向熵:衡量整个序列的总体不确定性
- 局部熵:识别特定时期的局部不确定性
注意
- 高局部熵 ≠ 负面发展,因为可能代表生活的”重组期”,也就是成长、转型的关键阶段
- 解读的时候,我们需要关注局部熵的峰值,并且结合具体背景分析,不要孤立看单一指标
通过局部熵,我们可以更精细地理解生命历程中的动态变化过程,发现那些看似平静但实际充满可能性的关键时期。
总结#
局部熵的实际应用场景
- 职业生涯研究
- 追踪职业状态的变化轨迹
- 识别职业转型的关键时期
- 生命历程分析
- 捕捉生活轨迹的不确定性
- 找出重大转折点
关键点
- 窗口是移动的”取样器”
- 每个窗口反映一个特定时间段的状态变化
- 熵值反映这个时间段的不确定性程度
总之,时间窗口分析帮助我们:
- 从宏观序列中提取局部特征
- 动态展示生命轨迹的变化
- 量化不同时期的复杂性